What Is This?
A scraper that trawls AO3 and FanFiction.net looking for stories that match specific criteria. Keyword filtering handles the obvious rejects, then a local LLM decides if the rest are actually worth reading.
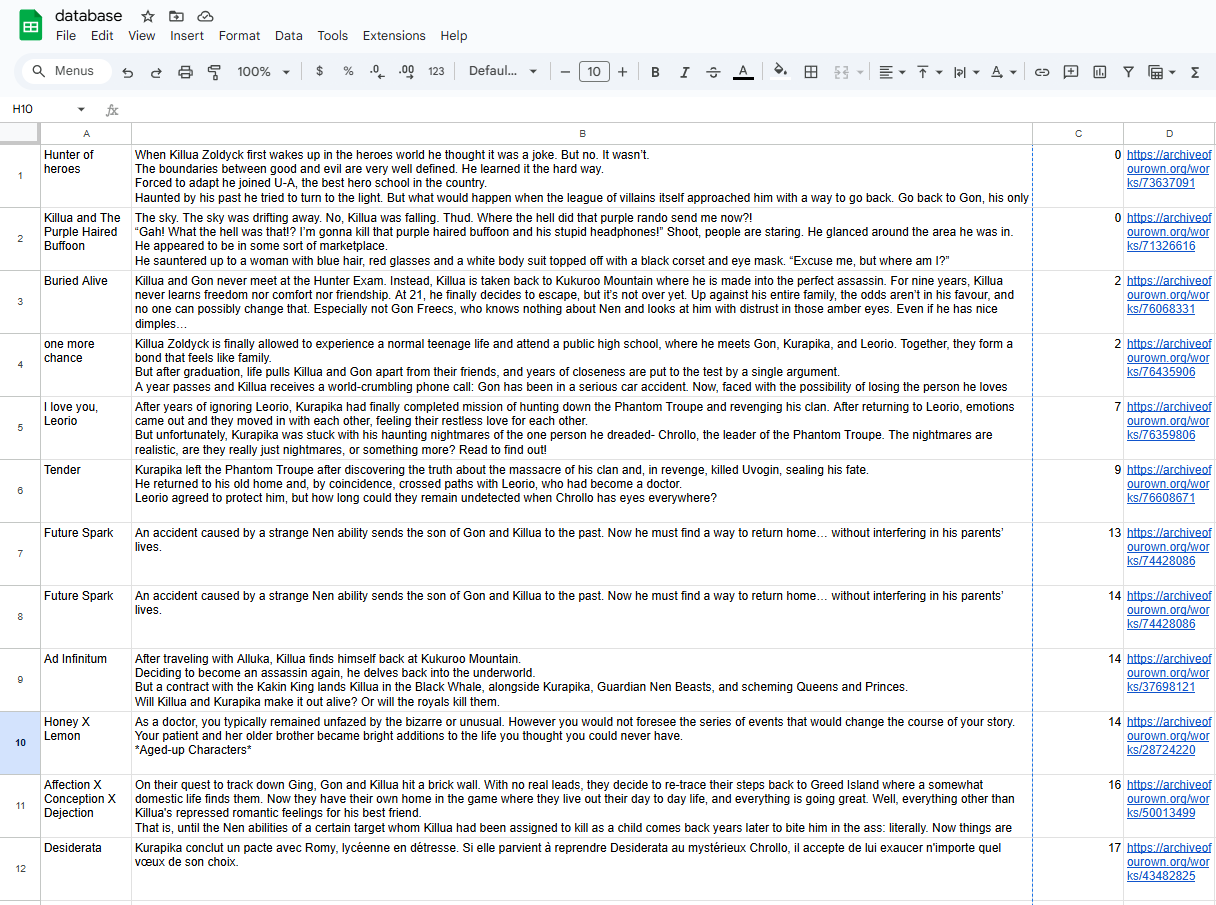
Matches get logged to a Google Sheet for later. The whole thing runs locally—no API costs, no rate limits.
The Two-Stage Filter
LLM inference is slow. Running every story through one would take forever. So the pipeline has two stages:
- Keyword filter — Fast substring matching against summaries. No keywords? Skip immediately.
- LLM classification — Stories that pass stage one get sent to Ollama for a real judgment call. The model returns True or False.
This cuts LLM calls by 50-90% depending on how selective your keywords are. Most stories don't make it past stage one.
Browser Automation
Standard Selenium gets blocked instantly on these sites. SeleniumBase in undetected-chromedriver mode gets around that—it masks the automation fingerprints that bot detection looks for.
The scraper handles CAPTCHAs automatically via uc_gui_click_captcha(), and uc_open_with_reconnect() retries on flaky connections. DOM extraction uses CSS selectors to pull titles and summaries from each page.
Site-Specific Scrapers
Each site needs its own module because the DOM structure differs:
- AO3 — Filters by fandom tag, 80k+ word count, sorted by update date. Pulls from
div.header.moduleand.userstuff.summary. - FanFiction.net — Filters by rating, length, and language. Uses
.stitleand.z-indent.z-padtop.
If either site changes their markup, the selectors break. That's the fragile part.
Local LLM
Classification runs through Ollama—phi4, phi4-mini, or deepseek-r1 depending on what you've got pulled. Temperature is set to 0 for deterministic outputs. The prompt tells the model to respond with a single word: True or False.
Parsing is just string matching. If the model gets chatty, it breaks. But with the right prompt, it doesn't.
Output
Matches append to a Google Sheet via gspread with OAuth2 service account auth. Each row gets title, summary, page number, and URL. Easy to scan through later and pick what to actually read.
Resumable Runs
Start and end pages are configurable constants. If a scrape gets interrupted, bump the start page and run again. Not sophisticated, but it works.